Configuration of the Neo4j Plugin #
The configuration of the SemSpect Plugin is split over two files: the (standard) Neo4j configuration file and the (optional) SemSpect configuration file as follows:
Neo4j Configuration File #
Remark: Some specific Neo4j configuration settings might depend on the Neo4j version.
HTTP(S) Server Configuration (required) #
To make SemSpect available at http(s)://<server>:<port>/semspect/, were the port is the advertised address of the HTTP connector
(same port as for Neo4j Browser, default 7474) you need the following minimal configuration:
Important
Do not simply copy the settings below into yourneo4j.conffile, but add the SemSpect setting values to the default or existing ones. The only exception isserver.jvm.additionalfor which you have to provide a separate entry for every parameter you want to specify.
server.unmanaged_extension_classes=de.derivo.semspect.server.neo4japp.server=/semspect
dbms.security.http_auth_allowlist=/,/browser.*,/semspect.*
Please also make sure that the user running Neo4j has rights to write into the plugin directory (see SemSpect Data Directory Location) and that you have placed the SemSpect plugin in this directory.
If the procedures security is active on your server, you must also allow access to the SemSpect procedures. If the access is denied you will get a “plugin not found” error even if the plugin was correctly installed. In the following example SemSpect is added to the procedures list that was restricted to the APOC procedures:
dbms.security.procedures.allowlist=apoc.*,semspect.*
(For more information, see the Neo4j documentation for unmanaged_extension_classes, http_auth_allowlist and allowlist)
Initialization Configuration (optional) #
SemSpect automatically initializes when a user opens SemSpect for a particular database of a DBMS. This initialization step is required for each user/database combination and can be configured as follows.
Multithreading for Initialization (optional) #
The number of threads used for the initialization of SemSpect at start-up and on any data change (default is the number of available processors of the host system) can be set by adding the following line:
server.jvm.additional=-Dde.derivo.semspect.server.init.threads=8
Note: In some environments such as docker the detection of available processors might not work correctly. In such cases the default value is 1.
Batch Size for Initialization (optional) #
The batch size used for the initialization (default is 1000) can be set by adding the following line:
server.jvm.additional=-Dde.derivo.semspect.server.init.batch_size=1000
SemSpect Data Directory Location (optional) #
The directory in which the SemSpect data is stored (default is semspect_data/ in the plugin directory of the Neo4j DBMS installation)
can be set by adding the following line:
server.jvm.additional=-Dde.derivo.semspect.server.data.path=/path/to/your/semspect_data
Note: Relative path declarations are resolved relative to the plugin directory of the Neo4j DBMS.
SemSpect Configuration File Location (optional) #
The path of the SemSpect configuration (default is ./semspect_config.yaml in the plugin directory of the Neo4j DBMS installation)
can be set by adding the following line:
server.jvm.additional=-Dde.derivo.semspect.server.configuration.path=/the_path_to/my_semspect_config.yaml
This path also specifies the location of your license file (if not otherwise specified in the SemSpect configuration file as described below).
Note: Relative path declarations are resolved relative to the plugin directory of the Neo4j DBMS.
SemSpect Main Configuration File (optional) #
The SemSpect main configuration file is optional and can be used to disable specific features globally
or for particular users or roles (semspect is enabled with all features for all users per default)
as well as to specify the license file location.
It is a YAML file (default name: semspect_config.yaml) with the following structure:
---
version: 2 # format of the configuration file
# optional license configuration
license:
file: "path to semspect license" # default semspect.lic
session-keep-alive-minutes: 15 # default 15
warn-before-session-expiration-minutes: 3 # default 3
# optional semspect features configutation for users
settings:
# default feature settings
semspect: true # enable/disable semspect globally
features: # enable/disable individual features.
FEATURE_KEY_1: true # e.g. customCategories: true|false
FEATURE_KEY_2: true
# role feature settings
roles: # overwrite 'default-settings'
- role: "admin"
semspect: true
features:
FEATURE_KEY_1: true
FEATURE_KEY_2: true
# user feature settings
users: # overwrite roles and 'default'-settings
- user: "neo4j"
semspect: true
features:
FEATURE_KEY_1: true
FEATURE_KEY_2: true
Settings➞semspect|features|roles|users #
The setting specification is organized according to the following schema:
settings ➞ semspect
➞ features ➞ [feature-key]
➞ roles ➞ [role-id] ➞ semspect
➞ features ➞ [feature-key]
➞ users ➞ [user-id] ➞ semspect
➞ features ➞ [feature-key]
Where role-id refers to a Neo4j role
and user-id to a user of the DBMS.
Note: The general feature settings are valid for all users but are overwritten by role specific feature configurations. Users can have multiple roles. In such a case a feature is enabled if it is enabled in at least one of the users roles. Furthermore, a specific user setting overwrites the settings given in the roles of the user.
Note: The SemSpect features enabled for a given user are available for all databases to which the user has been granted access on the DBMS (directly or through one of its roles).
The feature-keys are:
customCategoriesto enable/disable the usage of SemSpect labels.
(Reminder: The SemSpect labels are query based and will be recomputed after each modification of the graph data)savedExplorationsto enable/disable the storage of explorationsshowQueryto enable/disable access to the Cypher queries of each groupshowObjectIdInteractionsSettingto enable/disable the settings to show the Neo4j node IDs
License File Location #
To set the file name and location of your SemSpect license file (default is ./semspect.lic
in the same directory as the SemSpect main configuration YAML file) use:
license ➞ file:[path to semspect license]
Note: Relative path declarations are resolved relative to the directory of the SemSpect main configuration YAML file.
Session Expiry #
The number of concurrent SemSpect users is encoded within the license file. To set the time after which the session of an inactive user is expiring (default 15) use:
license ➞ session-keep-alive-minutes:[integer]
Moreover, to help prevent the session from expiring and possibly being given to another user when all available sessions are in use, a warning message before expiration can be enabled as follows:
license ➞ warn-before-session-expiration-minutes:[integer]
SemSpect Configuration Validation #
To test the configuration (syntax check) after modification use the following java command from the command line in the directory where the plugin and configuration are located:
% java -cp semspect_neo4j-plugin.jar de.derivo.semspect.server.TestConfiguration
If your configuration is located outside the plugin directory, add the following parameter to the java command:
-Dde.derivo.semspect.server.configuration.path=/the_path_to/my_semspect_config.yaml
#e.g.
% java -Dde.derivo.semspect.server.configuration.path=/tmp/my_config.yaml -cp semspect_neo4j-plugin.jar de.derivo.semspect.server.TestConfiguration
Reloading your Configuration #
To trigger a reloading of the configuration without restarting the DBMS use following command in Neo4j Browser:
CALL semspect.reloadConfig
Dossier Configuration #
For each DBMS, we can define the rendering type of property key values such that URLs become links or image URLs show the respective image etc. This is done in a separate dossier configuration.
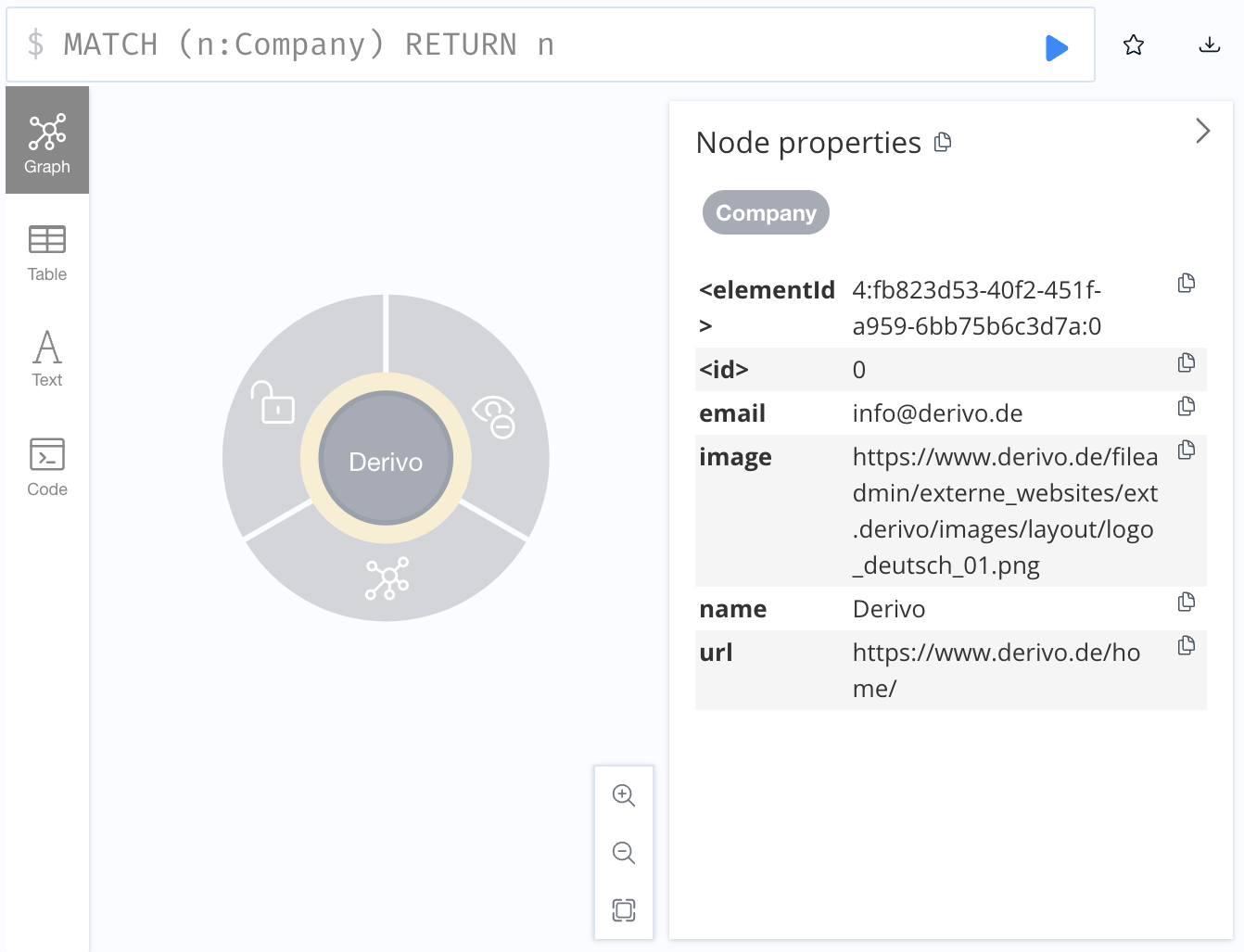
As an example, consider the following data about a node in a DBMS of name neo4j:
CREATE (derivo:Company
{ name: "Derivo",
image: "https://www.derivo.de/fileadmin/externe_websites/ext.derivo/images/layout/logo_deutsch_01.png",
email: "info@derivo.de",
url: "https://www.derivo.de/home/" })
In Neo4j Browser this node exposes as follows:
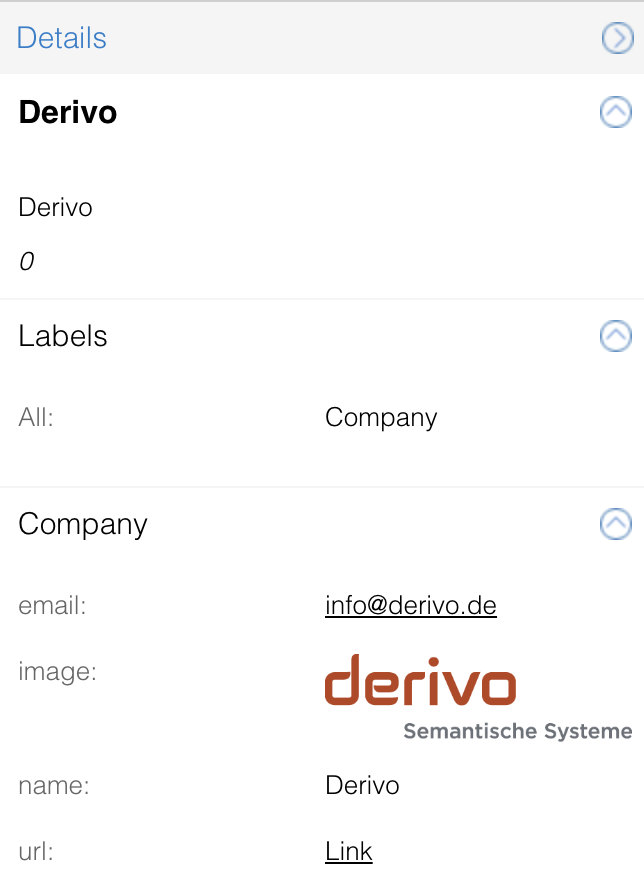
Now, to specify the UI types of the respective property keys (called attributes in the configuration), a YAML dossier configuration is required:
version: 1
databases:
- database: neo4j
attributes:
- id: 'image'
type: 'IMAGE'
- id: 'url'
type: 'URL'
- id: 'email'
type: 'EMAIL'
SemSpect is reading the dossier configuration by default from the following path:
<DBMS_HOME>/plugins/semspect_dossier_configuration.yaml
Result in SemSpect:
Facet Configuration (Experimental) #
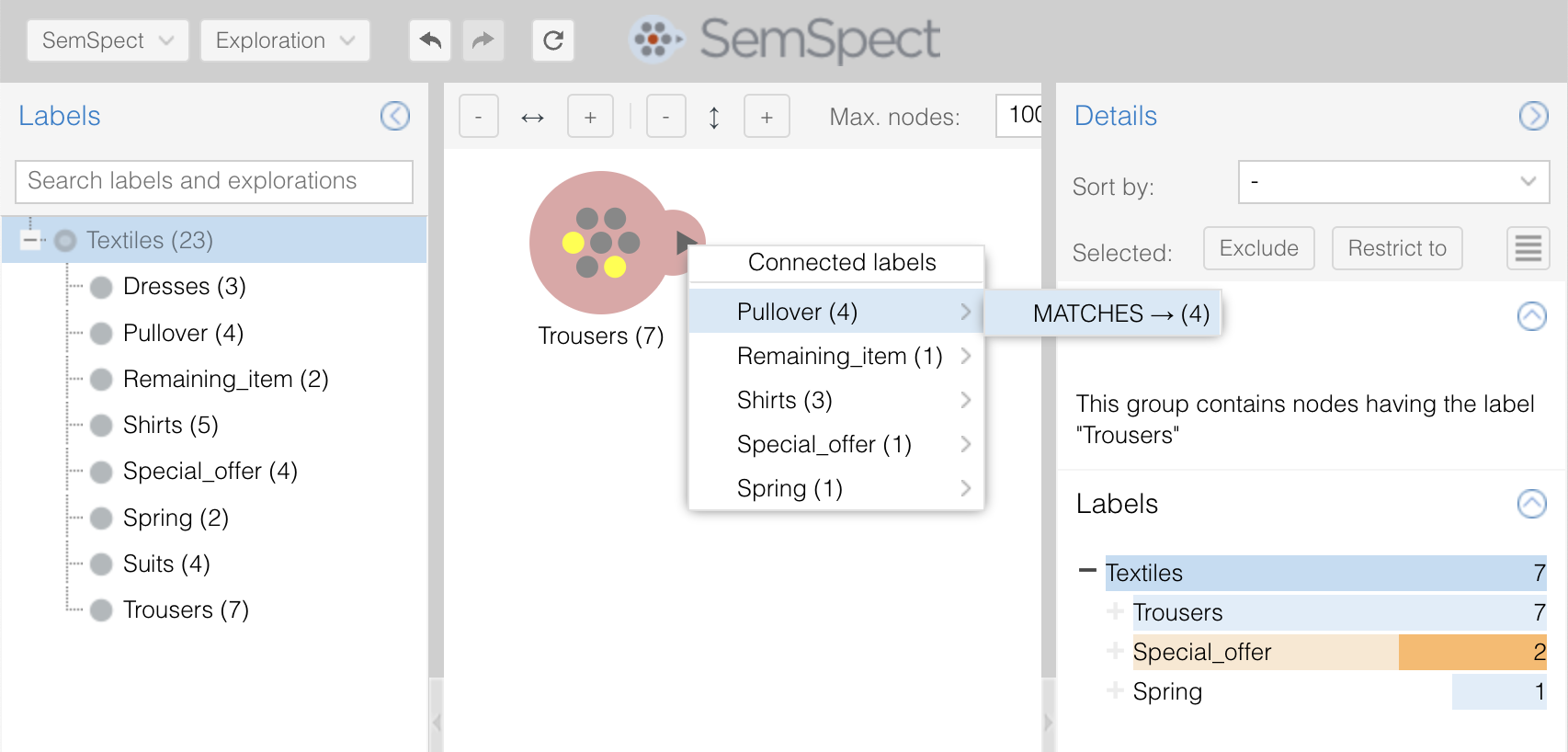
In SemSpect, facets are configurable filter for groups shown in separate sections of the dossier on the right-hand side. They behave in the same way as the label filters and can be collapsed or expanded in the case of a hierarchy. In fact, facets display labels from the list of labels. With the help of a facet configuration one can define which parts of the labels at which particular combination are shown as a separate facet. This is useful to distinguish between the backbone label schema and labels that provide a “second perspective” on the data. As an example, consider the following dataset that deals with clothes and their sales status:
In case our main focus is on the type of clothing (shirt, trousers etc.) it might be useful to declare the sales information as a facet. This has the advantage that the label tree and exploration menu becomes shorter (facets are not shown in the label tree and exploration menu). However, the facet labels are still available for filtering on those groups that contain nodes with those labels:
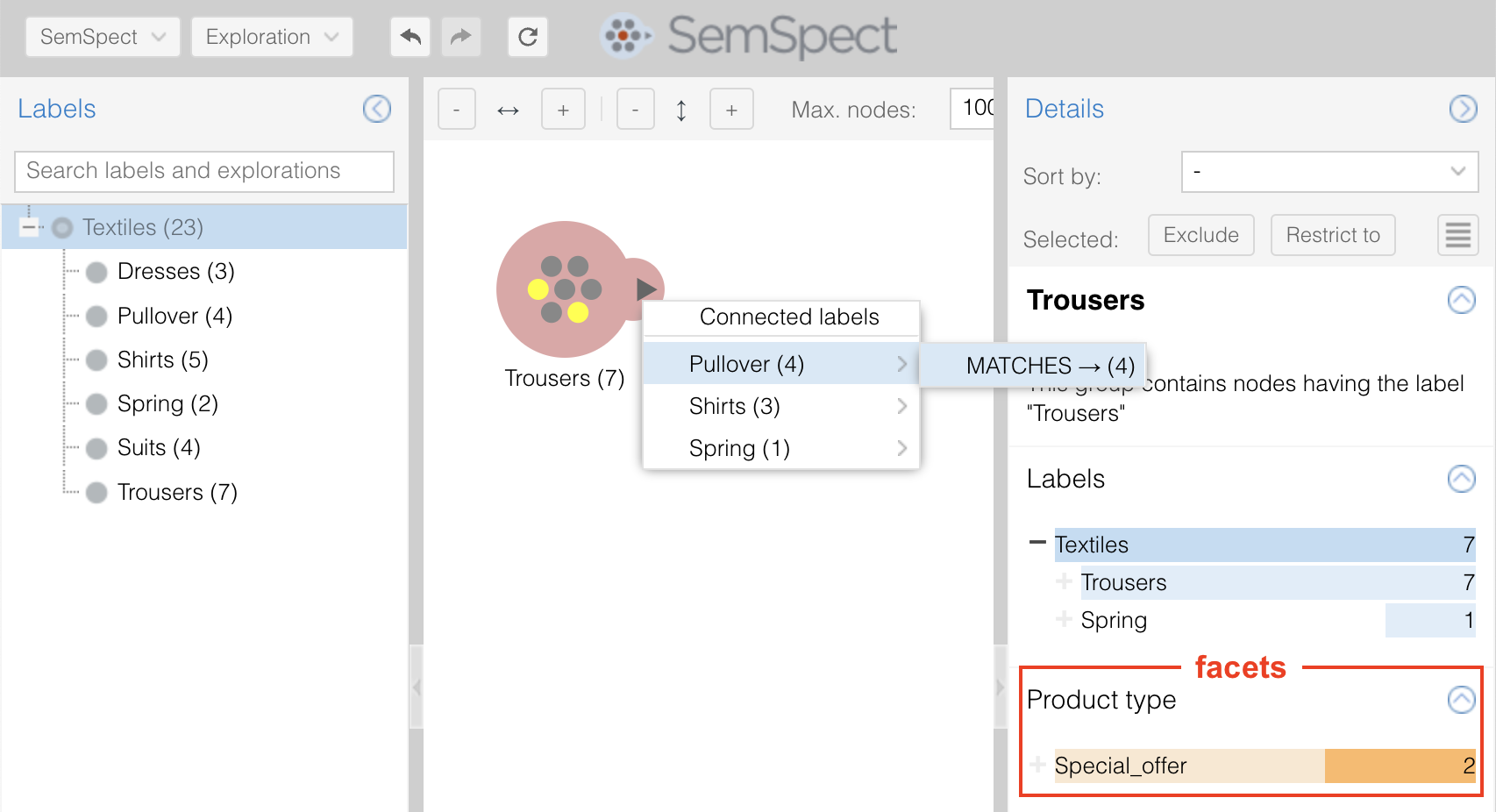
Please note that all specified labels of a facet no longer appear in the label tree view shown on the left, unless they also occur in a branch that is not declared as a facet.
Facets are defined in a facet configuration file. Each facet definition consists of one or more so-called facet values and a facet name. There are two types of facets:
simple(default): only the listed labels are used as facet values, not their sub-labels (unless they are also listed). This setting is mostly relevant for Neo4j SemSpect where the label hierarchies are computed from the data.
Remark: unlisted sub-labels of a simple facet labels will be moved up one level in the label tree and histograms (or hidden if they appear in a neighbour branch).subtree: the listed labels and all their sub-labels are used as facet values.
Remark: sub-labels of a subtree facet label that appear in other non facet branches of the label hierarchy can still be found there.
In the example above, the following facet definition was given:
version: 1
databases:
- database: neo4j
facets:
- name: 'Product type'
values: [ 'Special_offer',
'Remaining_item' ]
type: simple
Click to expand the matching Neo4j data of this example
create (:Textiles:Trousers {name: "trouser1"});
create (:Textiles:Trousers:Special_offer {name: "trouser2"});
create (:Textiles:Trousers {name: "trouser3"});
create (:Textiles:Trousers:Spring {name: "trouser4"});
create (:Textiles:Trousers {name: "trouser5"});
create (:Textiles:Trousers:Special_offer {name: "short1"});
create (:Textiles:Trousers {name: "short2"});
create (:Textiles:Pullover {name: "pullover1"});
create (:Textiles:Pullover {name: "pullover2"});
create (:Textiles:Pullover:Remaining_item {name: "pullover3"});
create (:Textiles:Pullover {name: "pullover4"});
create (:Textiles:Shirts:Special_offer {name: "shirt1"});
create (:Textiles:Shirts {name: "shirt2"});
create (:Textiles:Shirts:Spring {name: "shirt3"});
create (:Textiles:Shirts {name: "tshirt1"});
create (:Textiles:Shirts {name: "tshirt2"});
create (:Textiles:Dresses {name: "dress1"});
create (:Textiles:Dresses {name: "dress2"});
create (:Textiles:Dresses:Remaining_item {name: "dress3"});
create (:Textiles:Suits {name: "suit1"});
create (:Textiles:Suits:Special_offer {name: "suit2"});
create (:Textiles:Suits {name: "suit3"});
create (:Textiles:Suits {name: "suit4"});
match (n1 {name: "trouser1"}), (n2 {name: "pullover1"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser1"}), (n2 {name: "shirt1"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser2"}), (n2 {name: "pullover1"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser2"}), (n2 {name: "pullover2"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser3"}), (n2 {name: "pullover3"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser4"}), (n2 {name: "pullover4"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser4"}), (n2 {name: "shirt3"}) create (n1)-[:MATCHES]->(n2);
match (n1 {name: "trouser4"}), (n2 {name: "shirt2"}) create (n1)-[:MATCHES]->(n2);
SemSpect is reading the facet definitions from the following file (if existent):
<DBMS_HOME>/plugins/semspect_facets.yaml
Category Configuration (Experimental) #
Remark: Since this configuration is shared by the Neo4j and RDF versions of SemSpect, it uses the generic terms
categories and id in the configuration file. In the Neo4j case these should be understood as labels and node ID.
Captions and descriptions provide essential textual representations of nodes within an exploration.

These representations are either the value of a user-adjustable property key of the node or the node’s ID. Captions are used as primary text elements, appearing as titles or flag labels when specific nodes are highlighted. Descriptions are secondary text elements that are shown as supplementary information under headers or in tooltips. The caption and description of the nodes can be set for each label via the context menu within the label tree.

Neo4j SemSpect selects for each label a default property key among those used by its instances using following prioritized list of java regular expressions:
- Caption:
(?i)name > (?i)title > (?i).*name.* > (?i).*title.* > .+ - Description:
(?i).*description.* > (?i).*comment.* > .+
The smallest property key of the first matching pattern is selected (for the description, we exclude the property key selected as default for the caption). If none of the nodes of the label has a property key, we default to the node ID.
This default behaviour can be modified by adding a configuration file that defines the default properties keys for captions and descriptions of some classes, which can be overridden by the user.
As an example, consider the following dataset:
CREATE (germany:Country:Place {countryName: "Germany", countryCode: "DE"});
CREATE (ulm:City:Place {cityName: "Ulm", postalCode: "89073"});
CREATE (coordinate1:Building:Place {buildingName: "Ulmer Münster", coordinates: point({latitude: 48.398537, longitude: 9.992537})});
We use java regular expression to define which property key should be used as default caption/description.
---
databases:
- database: neo4j
categories:
- id: 'semspect::top' # special category 'TOP'. Fallback if no other configuration matches.
caption:
regex:
- "(?i).*name" # use some property key ending on name
- "\\Qsemspect::object_id\\E" # semspect::object_id is a special reference for the ID of the node
description:
regex:
- "\\Qsemspect::object_id\\E"# semspect::object_id is a special reference for the ID of the node
- id: 'Place'
description:
regex:
- '(?i).*code' # use some property key ending on code
- id: 'Country'
caption:
regex:
- '(?i).*code' # use some property key ending on code
description:
regex:
- "(?i).*name" # use some property key ending on name
We use a “nearest matching super-label”, strategy to select which property keys to use for caption and description. The strategy involves evaluating super-labels in the inferred label tree
We first select a label with matching regex as follows:
- If a regular expression was defined for the label itself, and it has at least one property key matching one of the regular expressions, the label itself is a match.
- If no regular expression was defined for the label itself or none of its properties matched, we collect the parent
labels and repeat the process level by level, until at least a match is found among the ancestors.
- If multiple matches occur at the same level, we select an ancestor label in a deterministic but unspecified manner.
- If no match is found, we default to the definition of
semspect::top.
We then select a matching property key:
- The first matching regular expression is selected
- If multiple properties match the selected regular expression, we select one of them in a deterministic but unspecified manner.
- If we defaulted to
semspect::topand no regular expression matches, we default to the node’sID.
In the example above:
- The default caption of
CountryiscountryCodesince the regular expression(?i).*codematches. - The default description of
CountryiscountryNamesince the regular expression(?i).*namematches. - The default caption of
CityiscityNamesince the nearest super-label with a matching regex issemspect::topwith(?i).*name". - The default description of
CityiscityCodesince the nearest super-label with a matching regular expression isPlacewith(?i).*code. - The default caption of
BuildingisbuildingNamesince the nearest super-label with a matching regex issemspect::topwith(?i).*name". - The default descriptions of
Buildingis the node ID since the nearest super-label with a matching regex issemspect::topwith\\Qsemspect::object_id\\E.
Remark: most of the use cases should be easily configurable with regex lists ordered by preference for the caption
and description for semspect::top (or for a handful of top classes indicating provenance of the data in heterogeneous
datasets).
SemSpect is reading the dossier configuration by default from the following path:
<DBMS_HOME>/plugins/semspect_category_configuration.yaml